Romain Mathonat
I am a
The internet has greatly helped me in my work, so I contribute my share through various open-access publications.
Projects

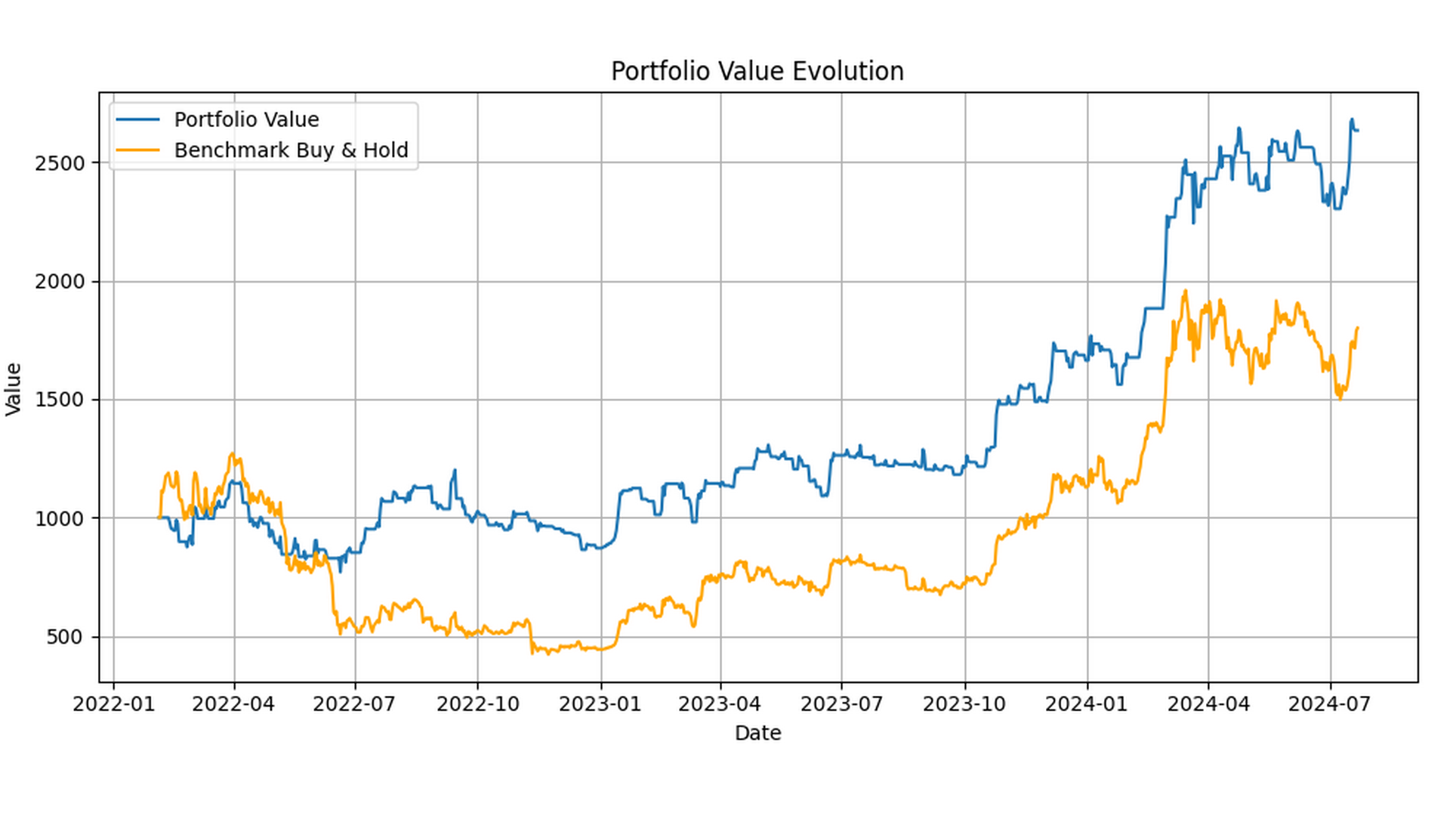
Analysis of financial markets and cryptocurrencies, backtesting of numerous strategies

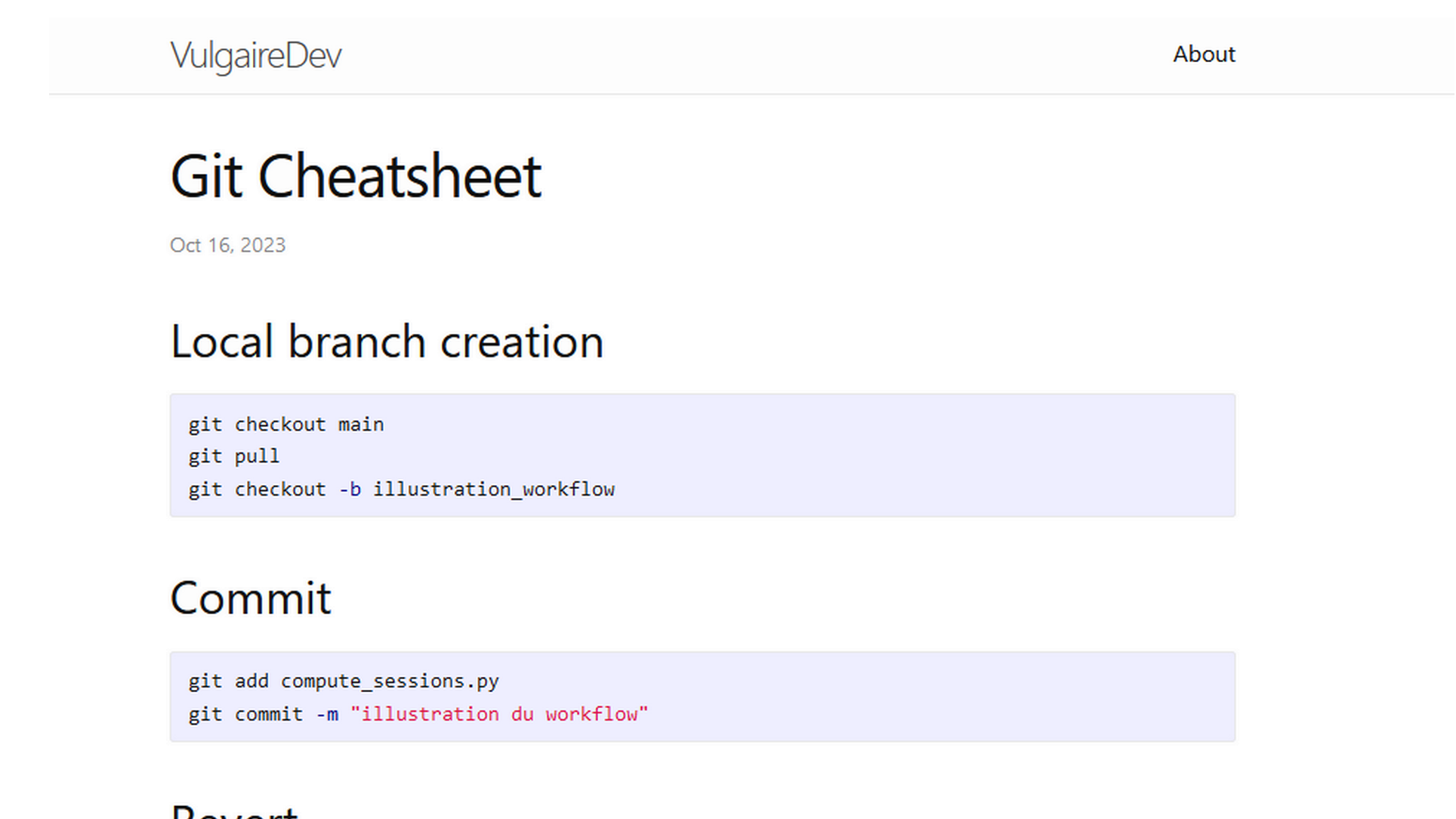
Publications of scientific and technical popularization articles

Experience

Project Implementation and improvement of mobility data pipelines
Context The Michelin Mobility Intelligence (MMI) entity's mission is to make road infrastructures safer, better quality, and more ecological. To achieve this, mobility data is collected and stored in the data warehouse, then transformed and used by various machine learning algorithms to provide prediction and analytics to the client.
Missions
- Implementation of high-volume data pipelines (~100 billion/month)
- Improvement of CI/CD (performance/ease of use)
- Modernization of the python dependency system, overhaul of wheel storage and build
- Team training on best practices/tools (TDD, hexa archi, pdm, ruff, wsl, vsCode)
- State of the art (data sharing)
- Development of internal performance monitoring library
- Dashboarding and dataviz
Technical environment
Snowflake, snowpark (equivalent to pyspark), SQL, python, CI/CD, pytest, Microsoft Azure, Databricks, Grafana, Streamlit, Gitlab

Project Implementation and improvement of mobility data pipelines
Context Infologic is an SME that provides an ERP in the agri-food sector. In this context, a lot of data is available, both user behavior data and technical server operation data. This data was underutilized, so it was necessary to create an architecture to store it and then use it for various needs: preventive maintenance, ergonomic problem detection, user tracking, etc.
Missions
- Data modeling and implementation of the data warehouse
- Training in best practices for data scientists
- Securing and installing solutions on machines (devops)
- Implementation of data pipelines
- Development of an in-house monitoring solution
- State of the art on scientific topics (clustering, LLM)
- Popularization and communication to the business
Technical environment
Python, SQL, Clickhouse, ElasticSearch, Bare metal, notebooks, Jupyter Hub, java

Project Implementation and improvement of mobility data pipelines
Context In collaboration with a startup: FUL. The business model was to grow plants in controlled growing environments: growing melons in Japan becomes possible. My mission was then to collect operating data from this urban farm, to consolidate the data in order to train algorithms for predicting plant growth
Missions
- Data collection (ETL)
- Data visualization
- Implementation of an electricity consumption prediction model
- Participation in steering committees
- Implementation of a "human in the loop" model for improving plant growth recipes
Technical environment
Python, SQL, Linux, pytest, Git, SQLite, Grafana

Project Research, invention of interpretable rule discovery algorithms for sequential data, applied to e-sports
Context This thesis focused on creating new algorithms to perform data mining on sequential and temporal data. I applied this work to input sequences and 3D information from the game "Rocket League". This led to various publications, as well as the ability to detect user behaviors that were previously undetectable, which particularly interested various players in the field (startups, Ubisoft).
Missions
- Scientific state of the art
- Self-training
- Creation of new algorithms
- Communication and popularization of my work
- Teaching
Technical environment
Python, SQL, Linux, Git, Pytest, notebooks
Education
Algorithms for automatic discovery of predictive rules for sequential data, application to e-sports and analysis of video game data (Rocket League)
INSA Lyon